คอลัมน์ “ความจริงจากโลกเสมือน” โดย สฤณี อาชวานันทกุล (มกราคม 2554)
สถาปัตยกรรมของอินเทอร์เน็ต: ลักษณะและนัยต่อความรับผิด
เมื่อโลกล่วงเข้าสู่ศตวรรษที่ 21 อินเทอร์เน็ตก็ได้กลายเป็นปัจจัยสำคัญในการดำรงชีวิตสำหรับคนส่วนใหญ่ที่เข้าถึงอินเทอร์เน็ต ไม่ว่าจะเป็นเด็กเล็กที่ชอบเล่นเกมออนไลน์ คนหนุ่มสาวที่ใช้อินเทอร์เน็ตเป็นพื้นที่หลักในการรับรู้และแลกเปลี่ยนข้อมูลข่าวสาร ไปจนถึงคนเฒ่าคนแก่ที่มีความสุขกับการได้กลับมาพบปะพูดคุยกับเพื่อนเก่าอีกครั้งผ่านเฟซบุ๊ก
ยิ่งอินเทอร์เน็ตกลายเป็นส่วนหนึ่งในชีวิตประจำวันของเราเท่าไร เราก็ยิ่งมีแนวโน้มที่จะมองไม่เห็นความซับซ้อนเชิงโครงสร้างและความเรียบง่ายเชิงหลักการของอินเทอร์เน็ต และการที่เราได้อ่านข้อความบนหน้าเว็บเพจ (web page) แทบจะในทันทีที่เราเรียกดู ก็ทำให้เราไม่ฉุกใจคิดว่ามีผู้เกี่ยวข้องกี่ราย มีอะไรเกิดขึ้นบ้างก่อนที่เนื้อหาบนหน้าเว็บจะเดินทางมาถึงสายตาของเรา
ชาญชัย ชัยสุขโกศล ศูนย์ศึกษาและพัฒนาสันติวิธี มหาวิทยาลัยมหิดล อธิบายอย่างรวบรัดชัดเจนในรายงานเรื่อง “อำนาจเชิงโครงสร้างของเทคโนโลยี: ศึกษากรณีอินเทอร์เน็ตไทย ช่วงก่อนรัฐประหาร 2549” ว่า การที่เราได้อ่านหรือพิมพ์เนื้อหาบนอินเทอร์เน็ตนั้น มีผู้รับผิดชอบจำนวนมากในเครือข่าย ซึ่งเราอาจแบ่งได้เป็น 3 ชั้น ได้แก่
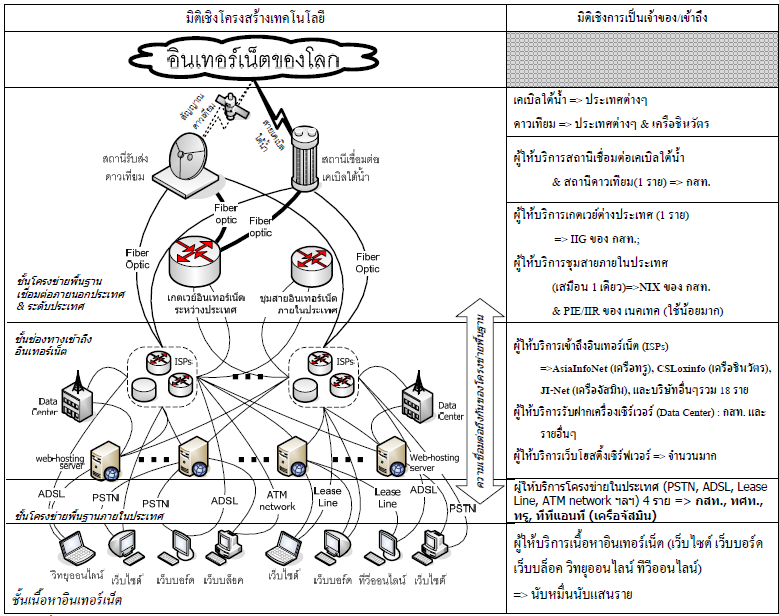
(1) ชั้นโครงข่ายพื้นฐาน (Network Infrastructure) ได้แก่ โครงข่ายโทรคมนาคม, วงจรเช่า (leased line / circuit), สายส่งสัญญาณ/สายโทรคมนาคม (transmission / telecommunication line), เกตเวย์อินเทอร์เน็ตระหว่างประเทศ (International Internet Gateway: IIG) ทำหน้าที่คล้ายชุมสายโทรศัพท์ (สำหรับการสื่อสารแบบโทรศัพท์) สำหรับโทรออกต่างประเทศ, ชุมสายแลกเปลี่ยนข้อมูลอินเทอร์เน็ตในประเทศ (National Internet Exchange: NIX)
(2) ชั้นช่องทางเข้าถึงอินเทอร์เน็ต (Internet Access) ประกอบด้วยบริการหลักๆที่เกี่ยวข้อง 3 ประเภท ผู้ให้บริการอินเทอร์เน็ต (ISPs), บริการเว็บโฮสติ้ง (webhosting) หรือรับฝากเว็บไซต์ และศูนย์ข้อมูล (Data Center) ซึ่งให้บริการรับฝากเครื่องเว็บเซิร์ฟเวอร์ และ
(3) ชั้นเนื้อหาอินเทอร์เน็ต (Internet Content) ซึ่งประกอบด้วยเว็บไซต์, เว็บบอร์ด, เว็บบล็อก (weblog), ทีวีออนไลน์, วิทยุออนไลน์, เว็บเครือข่ายสังคม (social network site) ฯลฯ
อาจารย์ชาญชัยสรุปต่อไปว่า การที่เราสามารถเข้าถึงเนื้อหาอินเทอร์เน็ตหนึ่งๆ (เช่น เว็บไซต์แห่งหนึ่ง) ได้นั้น จำเป็นต้องอาศัยเทคโนโลยีชนิดต่างๆมากมายมหาศาล ที่เชื่อมต่อกันเป็นระบบเทคโนโลยีอินเทอร์เน็ตขนาดใหญ่ และทำงานร่วมกันในการรับส่งข้อมูลระหว่างอุปกรณ์ต่างๆ ดังนี้ (ดูตารางประกอบ)
(1) เราเองจะต้องเชื่อมต่อกับระบบอินเทอร์เน็ต โดยล็อกอินผ่านระบบการให้บริการช่องทางการอินเทอร์เน็ต (ISP) รายหนึ่ง จากนั้นจึงส่งข้อมูลคำสั่ง ว่าต้องการเปิดเว็บใดไปยังเครื่องเซิร์ฟเวอร์ของผู้ให้บริการอินเทอร์เน็ต (ในที่นี้จะเรียกว่า “บิต” (bit) ซึ่งเป็นเลขฐานสอง อันเป็นรูปแบบพื้นฐานที่สุดของภาษาคอมพิวเตอร์) (2) บิตคำสั่งดังกล่าวจะถูกส่งผ่านโครงข่ายโทรคมนาคมพื้นฐานเชื่อมต่อภายในประเทศทั้งที่เป็นแบบอินเทอร์เน็ตความเร็วสูง (ADSL) หรือระบบอินเทอร์เน็ตความเร็วต่ำ (PSTN) รวมทั้งระบบโครงข่ายเอทีเอ็มหรือสายเช่า (lease line) ประเภทต่างๆ เพื่อเรียกข้อมูลจาก (3) คอมพิวเตอร์เซิร์ฟเวอร์ที่ทำหน้าที่เป็นเว็บโฮสติ้ง ซึ่งถ้าเป็นเว็บใหญ่ก็จะตั้งอยู่ที่ (4) ศูนย์ข้อมูล (Data Center) ซึ่งให้บริการรับฝากเครื่องเซิร์ฟเวอร์ด้วย ถ้าข้อมูลเนื้อหาอินเทอร์เน็ตไม่ได้อยู่ที่ระบบให้บริการอินเทอร์เน็ตนั้นๆ บิตคำสั่งขอข้อมูลดังกล่าวก็จะต้องวิ่งขึ้นไปที่อื่น กรณีเว็บนั้นๆอยู่ภายในประเทศ (เช่น pantip.com เป็นต้น) บิตคำสั่งจะวิ่งไปที่ (5) ชุมสายอินเทอร์เน็ตภายในประเทศ เพื่อวกกลับลงมาสู่ (6) ระบบให้บริการอินเทอร์เน็ตของรายอื่น ซึ่งเชื่อมต่อกับ (7) เว็บโฮสติ้งเครื่องที่เก็บข้อมูลของ (8) เว็บไซต์ตัวที่ต้องการเข้าถึง แต่ถ้าเว็บไซต์นั้นๆอยู่ต่างประเทศ (เช่น youtube.com เป็นต้น) คำสั่งขอข้อมูลก็จำเป็นจะต้องวิ่งไปที่ (9) เกตเวย์อินเทอร์เน็ตเข้า/ออกระหว่างประเทศ เพื่อวิ่งต่อโดยผ่าน (10) สายใยแก้วนำแสงภาคพื้นดินไปที่ (11) สถานีรับส่งดาวเทียม หรือ (12) ที่จุดเชื่อมต่อสายเคเบิลใต้น้ำ เพื่อออกสู่เครือข่ายอินเทอร์เน็ตของโลกต่อไป เมื่อได้พบเซิร์ฟเวอร์ที่ตั้งของเว็บไซต์นั้นๆ แล้ว บิตข้อมูลเนื้อหาของเว็บไซต์นั้นๆก็จะถูกส่งให้วิ่งย้อนกลับยังเครือข่ายอุปกรณ์ต่างๆตามที่วิ่งมา (กรณีนี้เป็นเพียงตัวอย่างพื้นฐาน กรณีจริง จะมีเทคนิคอีกมากมาย เพื่อลดความล่าช้าของการวิ่งหาข้อมูล เช่น ระบบพร็อกซี่เซิร์ฟเวอร์ที่ติดตั้งไว้ตามอุปกรณ์ต่างๆ เป็นต้น)
(ดัดแปลงจากบทความของ ชาญชัย ชัยสุขโกศล — คลิกที่รูป เพื่อดูขนาดเต็ม)
จากตารางด้านบนจะเห็นว่า การทำงานอะไรก็ตามของอินเทอร์เน็ตนั้นมีผู้เกี่ยวข้องจำนวนมาก ซึ่งส่วนใหญ่เป็นคนหรือเครื่องที่เรามองไม่เห็น การที่เราได้อ่านเนื้อหาบนเว็บเพจหน้าไหนก็ตาม (รวมทั้งบทความที่ท่านกำลังอ่านอยู่นี้ด้วย) จำต้องอาศัย “ตัวกลาง” จำนวนมาก ตั้งแต่ผู้เขียนเนื้อหา (อย่างเช่นผู้เขียนบทความนี้) เว็บมาสเตอร์ (webmaster) ผู้ดูแลเว็บ ผู้ให้บริการโฮสติ้งซึ่งเป็นเจ้าของคอมพิวเตอร์ที่เก็บบทความนี้ไว้ให้ดู ไปจนถึงผู้ให้บริการอินเทอร์เน็ต (ISP) ที่ท่านจ่ายค่าบริการเพื่อเชื่อมต่อเข้าถึงอินเทอร์เน็ต
ในเมื่อการนำส่งเนื้อหาบนเว็บเพจสู่สายตาคนอ่านมีตัวกลางที่เกี่ยวข้องจำนวนมากและหลากหลายประเภท ผู้บังคับใช้กฎหมายจึงต้องใช้ความระมัดระวังและความเชี่ยวชาญค่อนข้างมากในกระบวนการพิสูจน์ว่า เนื้อหาบนเว็บไซต์ที่ผิดกฏหมายนั้นมี “ตัวกลาง” คนไหนที่มี “เจตนา” หรือ “ยินยอม” ให้สร้างเนื้อหาดังกล่าวบ้าง
ลองสมมติว่าคุณเช่าบ้านพักอยู่แถวชานเมือง วันดีคืนดีมีคนมือบอนมาพ่นข้อความกล่าวหานักการเมืองชื่อดังบนกำแพงบ้าน มีคนถ่ายรูปเอาไว้ได้และอัพโหลดรูปขึ้นเว็บบอร์ดชื่อดังแห่งหนึ่งก่อนที่คุณจะลบทัน สมาชิกเว็บบอร์ดหลายคนเข้ามาวิพากษ์วิจารณ์อย่างสนุกสนานและส่งรูปนั้นต่อไปเป็นอีเมลลูกโซ่ รวมทั้งก็อปปี้รูปนั้นไปโพสต์บนเว็บอื่น นักการเมืองผู้ตกเป็นเป้าเข้ามาพบรูปถ่ายข้อความบนกำแพง รีบสั่งให้ทนายหาตัวตนของคนมือบอนเพื่อแจ้งจับในข้อหาหมิ่นประมาท
ถ้านักการเมืองรายนั้นไปแจ้งความขอให้ตำรวจจับคุณด้วย โดยอ้างว่าคุณ “ยินยอม” ให้คนมือบอนหมิ่นประมาทเขาเพราะไม่ได้ทำความสะอาดกำแพงอย่างทันท่วงที คุณย่อมรู้สึกว่าข้อกล่าวหาข้อนี้ไม่เป็นธรรม คำถามข้อต่อไปคือ ถ้าใช้เหตุผลแบบนี้ นักการเมืองคนนั้นก็อาจใช้เหตุผลทำนองเดียวกันแจ้งความจับเจ้าของบ้านที่ให้คุณเช่า (ในฐานะเจ้าของกำแพงที่ตีพิมพ์ข้อความหมิ่นประมาท) เจ้าของเว็บบอร์ดที่เปิดให้คนเข้ามาโพสรูปถ่ายได้อย่างเสรี (ในฐานะเจ้าของสื่อที่เผยแพร่เนื้อหาหมิ่นประมาท) รวมไปถึงบริษัทโฮสติ้งที่โฮสเว็บบอร์ดนั้นๆ (ในฐานะเจ้าของพื้นที่ของสื่อที่เผยแพร่เนื้อหาหมิ่นประมาท)
การฟ้อง “ตัวกลาง” ต่างๆ ในกรณีสมมุติข้างต้นฟังดูไม่เป็นธรรมอย่างไร การฟ้องร้อง “ตัวกลาง” ต่างๆ กรณีเกิดเนื้อหาผิดกฎหมายบนอินเทอร์เน็ตก็ไม่เป็นธรรมฉันนั้น เนื่องจากการทำงานของอินเทอร์เน็ตต้องพึ่งพาอาศัยตัวกลางจำนวนมาก ลำพังการปรากฏเนื้อหาที่เจ้าหน้าที่มองว่าผิดกฎหมาย ไม่ได้แปลว่าตัวกลางต่างๆ “เจตนา” หรือ “ยินยอม” ที่จะให้เนื้อหานั้นปรากฏ
ในเมื่อสถาปัตยกรรมของอินเทอร์เน็ตมีตัวกลางที่เกี่ยวข้องจำนวนมาก และการทำงานของตัวกลางเหล่านั้นก็จำเป็นต่ออินเทอร์เน็ต กฎหมายอินเทอร์เน็ตที่เป็นมาตรฐานสากลจึงคุ้มครองตัวกลางเป็นพื้น คือตั้งสมมติฐานไว้ก่อนว่าบริสุทธิ์ ไม่ใช่เพ่งเล็งว่าสมรู้ร่วมคิดกับผู้กระทำผิด กล่าวคือ เจ้าหน้าที่จะไม่แจ้งจับตัวกลางในข้อหาเจตนาหรือยินยอมให้มีเนื้อหาที่ผิดกฎหมาย จนกว่าจะพิสูจน์ได้อย่างชัดเจนว่ามีเจตนาจริงๆ เช่น สมมติว่าเจ้าหน้าที่เคยแจ้งเว็บมาสเตอร์ให้ลบเนื้อหาที่แสดงหลักฐานให้เห็นแล้วว่าผิดกฎหมายอย่างชัดเจน ภายใน 7 วันตามที่กฎหมายกำหนด แต่เว็บมาสเตอร์ไม่ยอมทำตาม เป็นต้น (ปัจจุบันกฏหมายไทยยังไม่มีขั้นตอนในการแจ้งลบเนื้อหาผิดกฏหมาย)
นอกจากจะต้องทำความเข้าใจว่าอินเทอร์เน็ตเดินได้ด้วยตัวกลางจำนวนมากแล้ว เราก็ยังต้องทำความเข้าใจด้วยว่า บริการต่างๆ บนอินเทอร์เน็ตแตกต่างจากบริการนอกเน็ตอย่างไร ยกตัวอย่างเช่น เว็บบอร์ด (web board) คือการสื่อสารสองทางระหว่างผู้ใช้เน็ตด้วยกัน ไม่ใช่ “สื่อมวลชน” แบบดั้งเดิมที่ต้องมีกองบรรณาธิการคอยกรองเนื้อหา ก่อน ตีพิมพ์ เว็บบอร์ดไหนที่เนื้อหาถูกกรองก่อน เว็บบอร์ดนั้นก็จะไม่ได้รับความนิยม เพราะผู้ใช้เน็ตอยากสื่อสารกันเองโดยที่ไม่มีใครมาเซ็นเซอร์ก่อนตีพิมพ์ การเซ็นเซอร์หรือปิดกั้นทำได้ หลัง จากที่เนื้อความที่สื่อสารกันปรากฏบนเว็บแล้วเท่านั้น
ผู้ดูแลเว็บบอร์ดขนาดใหญ่ที่ได้รับความนิยมสูงมาก อย่างเช่น pantip.com เปรียบเสมือน “พิธีกร” ในงานเลี้ยง ผู้คอยดูแลให้การสนทนาระหว่างแขกเหรื่อเป็นไปอย่างราบรื่น หรือเป็น “โอเปอเรเตอร์” ผู้ทำหน้าที่สับสายโทรศัพท์ มากกว่าจะเป็น “บรรณาธิการผู้พิมพ์ผู้โฆษณา” ของสื่อสิ่งพิมพ์
พิธีกรในงานเลี้ยงไม่ควรต้องร่วมรับผิดเวลาที่แขกในงานกระทำความผิดฉันใด ผู้ดูแลเว็บบอร์ด เจ้าของเว็บบอร์ด เจ้าของเว็บไซต์ที่เปิดให้ใครก็ได้เป็นเจ้าของเว็บบอร์ด บริษัทโฮสติ้ง และผู้ให้บริการอินเทอร์เน็ต ก็ไม่ควรต้องร่วมรับผิดเวลาที่ผู้ใช้เน็ตโพสเนื้อหาที่ผิดกฏหมายฉันนั้น.